
In the previous article, we’ve presented to you the famous containers orchestrator Kubernetes. In this article we will dig deep into the Kubernetes components and explain in detail how does Kubernetes work.
The Kubernetes high-level architecture:
To understand how does Kubernetes work, we will first start with the global architecture of Kubernetes:
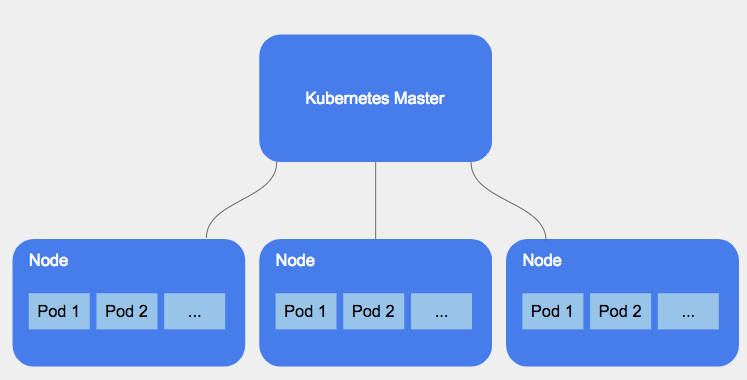
Kubernetes master node
The master node is the cluster control panel. This is where everything is managed such as scheduling and detecting/responding to events. Master processes can be ran on any node.
Kubernetes Worker Nodes
While the master manages and supervises the cluster, worker nodes run the containerized applications with providing the Kubernetes runtime environment.
To understand how does Kubernetes works, we need to take a deeper look into its components. So, the next step is to check the internal anatomy of the Kubernetes architecture.
The Kubernetes detailed architecture:
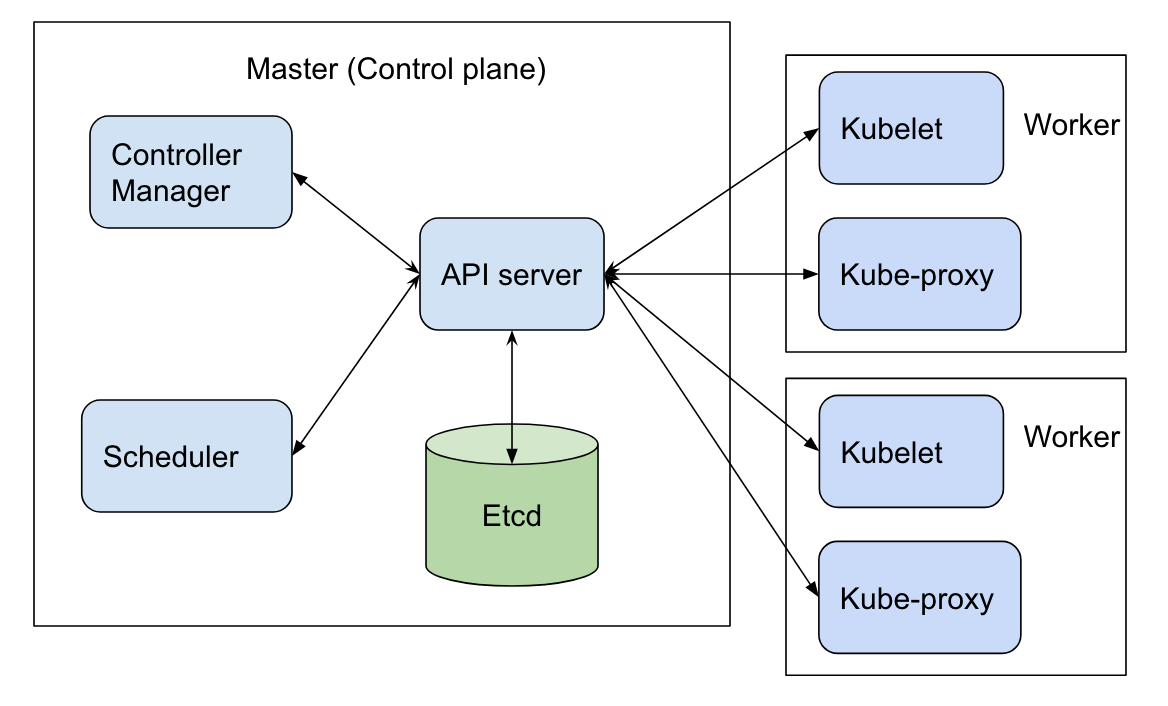
Focusing on the Kubernetes master, we find:
- API Server: The Kubernetes control panel component with a user-accessible API and the master interface that you’ll interact with. The API server exposes the Kubernetes restful API.
- ETCD Data Store: Kubernetes uses “etcd.” This is a strong, consistent, and highly available key value store that Kubernetes uses for persistent storage of all API objects.
- Controller Manager: or also the “kube-controller manager,” it manages all the controllers that treats routine tasks. This includes the Node Controller, Replication Controller, Endpoints Controller, and Service Account and Token Controllers: each one of them works separately to maintain the desired state.
We have also Cloud Controller Manager which was initiated from Kubernetes 1.15 beta version: this is quite a new component intended to separate cloud/infrastructure provider specific controller role from generic Kubernetes controllers. As from Kubernetes version 1.15, the cloud provider related functionality can still be implemented by the Controller Manager. Yet, it will soon move completely to Cloud Controller Manager.
- Scheduler: It watches for newly created pods (groups of one or more containers) and allocates them to nodes.
Now if we focus on the Kubernetes Worker Nodes, we will find:
- Kubelet: the primary node agent. It watches the API server for pods allocated by the scheduler to its node. The kubelet transmits tasks and maintains a reporting log of pod status to the master node.
Inside each pod there are containers, the kubelet executes these tasks generally via Docker (to pull images, requests to start and stop containers, etc.).
- kube-proxy: the main network of the node which maintains network rules on the host and performs connection forwarding. It’s also responsible for load balancing between all pods of the service.
If you go back few lines up, we’ve mentioned the word “Pod” few times. So,
What is a Pod?
A pod is a group of one or more containers sharing storage/network. Each pod contains specific details of how containers should be run. They can be considered as an isolated environment to run containers.
They are also the scaling unit. App components are scaled up or down by adjusting pods’ number.
In the case of tightly connected containers can run in a single pod (where each shares the same IP address and mounted volumes). If not, each container runs in its own pod.
A Pod is deployed on a single node and have a definite lifecycle. It can be pending, running, succeeding, or failing. But, once terminated, they are never brought back. And a replication controller must create a new one to try to keep the required number of pods running.
After specifying the core components of Kubernetes, we shall move to specify the main objects it’s based on.
So,
What are Kubernetes main objects?
To better understand how does Kubernetes work, we have to take a look at its main objects:
- Pods: an isolated environment that doesn’t play a main role except for hosting and grouping containers.
- Services: A Kubernetes object that describes a set of pods that provide a useful service. Services are typically used to expose a set of uniform pods.
- Persistent Volumes: an abstraction for persistent storage. For that, Kubernetes supports many kinds of volumes, such as NFS, Ceph, GlusterFS, local directory, etc.
- Namespaces: a concept that is used to group, separate, and isolate groups of objects.
- Ingress rules: used to specify how different types of traffic should be routed to services and pods.
- Network policies: used to defines the access rules between pods inside the cluster.
- ConfigMaps and Secrets: Used to detach configuration information from application definition.
- Controllers: These implement different rules for automatic pod management. There are three main types:
-
- Deployment: Responsible for preserving a set of running pods of the same type.
- DaemonSet: Runs a precise type of pod on each node based on a condition.
- StatefulSet: Used when several pods of the same type have to run in parallel, but each of the pods is required to have a specific identity.
Generally, Kubernetes objects can be created directly through the Kubernetes CLI kubectl. They can also be specified, described through YAML files and then applied through the same CLI. Or they can be created from REST API.
Kubernetes cluster
A cluster is all of these components put together as a single unit: A cluster consists of at least one master node and multiple worker nodes. These master and node machines run the Kubernetes cluster orchestration system.
Kubernetes supports actually several container engines, and Docker is the most famous one of them. Docker and Kubernetes, since Docker containers are an efficient way to deliver packaged applications, and Kubernetes is designed to manage and schedule those applications which creates our cluster based on Kubernetes’s containerized components and the containerized application itself
In Kubernetes, nodes adjust together their resources to form a more powerful logical machine. When you deploy applications onto the cluster, it automatically handles distributing work to the individual nodes. If any nodes are added or removed, the cluster will shift this modification. So, it shouldn’t matter to the application, or the programmer, which individual machines are actually running the code.
So here, to understand how does Kubernetes work, we need to admit that:
The Kubernetes objects works together to deploy your application within the cluster!
A Deployment runs multiple replicas of your application and automatically swaps any instances that fail or become unresponsive. Kubernetes Deployments help ensure that at least a minimum number of instances of your application are available to serve user requests. Deployments are managed by the Kubernetes Deployment controller. It’s right that Kubernetes has different kind of deployment that we mentioned above, but they have all the same general concept.
Once a deployment is created, identical instances or Pods of the application should be running. Each version of the application is managed by its own ReplicaSet that controls the identical Pods of the application in a specific deployment. And in the end, all these Pods are exposed through service objects which makes the endpoint to the deployed application.
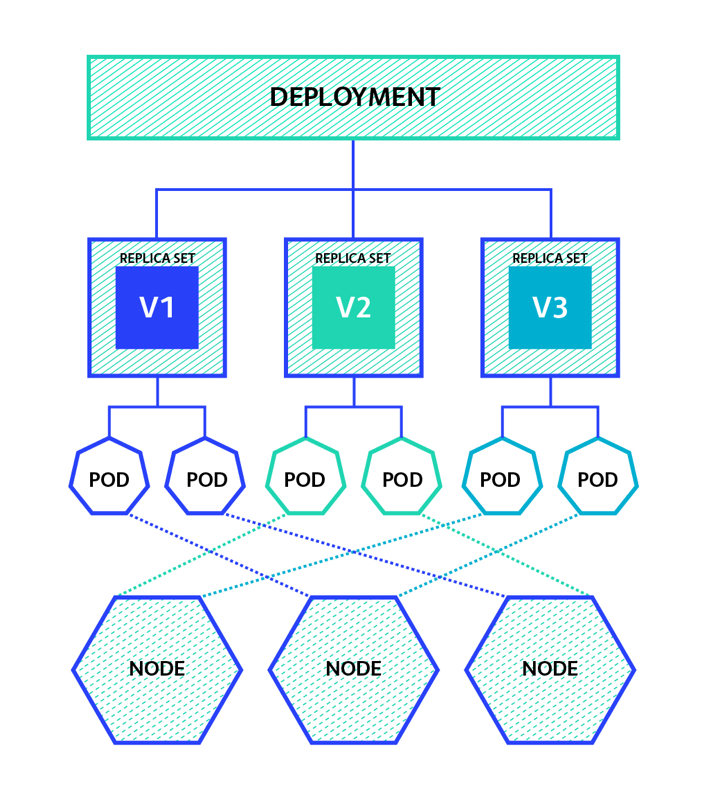
We briefly explained how does Kubernetes work through defining its main objects and concepts. We will explain all these details in the future tutorials thought interactive examples.